How to Solve Assignments on Naive Bayes for Resume Selection with Machine Learning

Claim Your Discount Today
Get 10% off on all Statistics homework at statisticshomeworkhelp.com! Whether it’s Probability, Regression Analysis, or Hypothesis Testing, our experts are ready to help you excel. Don’t miss out—grab this offer today! Our dedicated team ensures accurate solutions and timely delivery, boosting your grades and confidence. Hurry, this limited-time discount won’t last forever!
We Accept









- Why Naive Bayes for Resume Selection?
- Step 1: Understanding the Theory Behind Naive Bayes
- Step 2: Data Preprocessing – Cleaning and Preparing Resumes
- Removing Stop Words and Punctuation
- Tokenization
- Lowercasing and Normalization
- Vectorization
- Step 3: Building the Pipeline in Python
- Step 4: Evaluating the Model
- Step 5: Interpreting the Results
- Step 6: Skills Practiced Through the Assignment
- Step 7: Common Challenges and How to Overcome Them
- Step 8: Extending Beyond Naive Bayes
- Conclusion
Machine learning has become a cornerstone of modern statistics coursework, especially in assignments that focus on classification and prediction. Among the many algorithms used, the Naive Bayes classifier stands out as a simple yet highly effective method for text classification. Its applications go far beyond academic exercises, powering real-world tasks such as spam detection, sentiment analysis, and automated resume screening. For students, assignments involving Naive Bayes offer an excellent opportunity to combine theory with practice by building end-to-end pipelines that handle unstructured text, perform preprocessing, and generate predictive insights. Such assignments typically require data cleansing, tokenization, and vectorization before applying the model to classify resumes into shortlisted or rejected categories. Along the way, students gain hands-on experience with Python, Scikit-learn, Pandas, Matplotlib, and other essential libraries while developing strong foundations in data manipulation, visualization, and model evaluation. This process not only enhances academic performance but also prepares students for practical roles in data science and recruitment analytics. If you are struggling with these steps, expert guidance is always available through statistics homework help, ensuring you master both the concepts and the coding. You can also seek help with machine learning assignment tasks to handle the technical challenges confidently and achieve better results.
Why Naive Bayes for Resume Selection?

Before diving into the technical steps, let’s address the question: Why use Naive Bayes?
- Text classification-friendly: Naive Bayes works extremely well with text data, making it a natural choice for tasks like categorizing resumes into “shortlisted” or “not shortlisted.”
- Simple yet powerful: It relies on Bayes’ theorem with a strong independence assumption between features. Despite this assumption being “naive,” the results are often surprisingly effective.
- Fast and scalable: Naive Bayes is computationally efficient, which makes it suitable for large resume datasets.
- Baseline model: It often serves as a good baseline for text classification problems before moving to more complex models like Support Vector Machines or Neural Networks.
Step 1: Understanding the Theory Behind Naive Bayes
At its core, the Naive Bayes classifier is built on Bayes’ theorem:
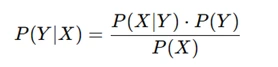
Where:
- Y is the class label (e.g., “selected” or “rejected”),
- X represents the features extracted from resumes (e.g., words or tokens),
- P(Y∣X) is the probability of class Y given the features X.
The “naive” assumption is that all features (words) are independent of one another given the class label. While this assumption rarely holds in reality, it simplifies computations and often performs surprisingly well.
For resume selection, this means:
- We calculate the likelihood of a resume being shortlisted based on the words it contains.
- Common skills like “Python,” “Data Analysis,” or “Machine Learning” might increase the probability of selection.
- Words like “beginner” or “internship” might reduce it, depending on the training dataset.
Step 2: Data Preprocessing – Cleaning and Preparing Resumes
Working with resumes means handling unstructured data. Raw text cannot be directly fed into machine learning models, so we need a data pipeline for text preprocessing.
Removing Stop Words and Punctuation
Stop words (like is, the, a, of) don’t carry useful meaning in classification. Similarly, punctuation marks add noise. Using Scikit-learn’s CountVectorizer or TfidfVectorizer, you can remove stop words automatically.
Tokenization
Tokenization breaks text into individual words (tokens).
For example:
- Resume text: “Experienced data analyst skilled in Python and SQL.”
- Tokens: [“Experienced”, “data”, “analyst”, “skilled”, “Python”, “SQL”].
Lowercasing and Normalization
To ensure consistency, words are usually converted to lowercase (e.g., “Python” → “python”). You might also use lemmatization or stemming to reduce words to their base forms.
Vectorization
Since machine learning models cannot work with raw words, we convert text into numeric vectors:
- Bag-of-Words (BoW): Counts word occurrences.
- TF-IDF: Considers both frequency and uniqueness of words across documents.
For resume selection, TF-IDF often works better since it reduces the importance of common but less discriminative words.
Step 3: Building the Pipeline in Python
In Python, you can create a pipeline that combines preprocessing, vectorization, and model training.
A simplified example looks like this:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import pandas as pd
# Example dataset (resumes and labels)
data = pd.DataFrame({
'resume': [
"Experienced data scientist skilled in Python and SQL",
"Intern with beginner knowledge of Excel and PowerPoint",
"Software engineer proficient in Java and machine learning",
"Marketing intern with exposure to social media campaigns"
],
'label': [1, 0, 1, 0] # 1 = shortlisted, 0 = rejected
})
# Split data
X_train, X_test, y_train, y_test = train_test_split(
data['resume'], data['label'], test_size=0.3, random_state=42
)
# Create pipeline
model = Pipeline([
('tfidf', TfidfVectorizer(stop_words='english')),
('nb', MultinomialNB())
])
# Train model
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
# Evaluation
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("Classification Report:\n", classification_report(y_test, y_pred))
This pipeline:
- Cleans the resumes (removes stop words).
- Converts text into TF-IDF vectors.
- Trains a Multinomial Naive Bayes classifier.
- Evaluates the model using accuracy, confusion matrix, and classification report.
Step 4: Evaluating the Model
Model evaluation is a crucial part of any statistics assignment. For resume selection, we use metrics like:
- Accuracy – Percentage of resumes classified correctly.
- Precision – Out of all resumes predicted as shortlisted, how many were actually shortlisted.
- Recall (Sensitivity) – Out of all shortlisted resumes, how many were correctly identified.
- F1-Score – Harmonic mean of precision and recall, balancing both.
- Confusion Matrix – A table showing true positives, false positives, true negatives, and false negatives.
Visualization helps in interpreting results. For instance, you can plot the confusion matrix using Matplotlib:
import matplotlib.pyplot as plt
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix - Resume Selection")
plt.show()
Step 5: Interpreting the Results
Once you train and evaluate the model, the next step in your assignment is interpretation.
- If accuracy is high (e.g., >85%), the model is performing well.
- If precision is higher than recall, the model is cautious about selecting resumes but might miss some good candidates.
- If recall is higher, the model is generous in selecting resumes but may include some unsuitable ones.
Depending on the assignment instructions, you may also need to tune hyperparameters (like smoothing parameter alpha in Naive Bayes) to improve results.
Step 6: Skills Practiced Through the Assignment
Completing a Naive Bayes resume selection assignment reinforces multiple technical skills, such as:
- Scikit-learn: Using machine learning libraries for building pipelines.
- Data Processing: Cleaning and transforming unstructured resume text.
- Python Programming: Writing scripts for data manipulation, model training, and evaluation.
- Data Visualization: Plotting confusion matrices and performance metrics.
- Natural Language Processing (NLP): Tokenization, stop-word removal, vectorization.
- Exploratory Data Analysis (EDA): Understanding resume data before modeling.
- Predictive Modeling: Applying machine learning to forecast candidate selection.
- Text Mining: Extracting patterns and keywords from resumes.
These skills not only help you solve your assignment but also prepare you for real-world applications in data science and recruitment analytics.
Step 7: Common Challenges and How to Overcome Them
Students often face challenges when working on Naive Bayes assignments. Here’s how to tackle them:
- Messy resume data: Resumes may contain bullet points, symbols, or inconsistent formatting. Use regex cleaning and text normalization techniques.
- Imbalanced classes: Often, fewer resumes are shortlisted compared to rejections. Apply resampling techniques like SMOTE or adjust class weights.
- Overfitting/Underfitting: If the model performs well on training but poorly on testing, tune the smoothing parameter or try different vectorization methods.
- Interpretability: To explain which words influence selection, extract feature log probabilities from the Naive Bayes model.
Example:
feature_names = model.named_steps['tfidf'].get_feature_names_out()
class_labels = model.named_steps['nb'].classes_
top_features = model.named_steps['nb'].feature_log_prob_
print("Top words for each class:")
for i, class_label in enumerate(class_labels):
top_indices = top_features[i].argsort()[-10:]
print(class_label, [feature_names[j] for j in top_indices])
This helps you identify keywords driving the classification decision.
Step 8: Extending Beyond Naive Bayes
For assignments that require comparisons, you can extend the analysis:
- Train other classifiers like Logistic Regression, Support Vector Machines, or Random Forests.
- Compare their performance with Naive Bayes.
- Discuss trade-offs in terms of accuracy, interpretability, and speed.
This makes your assignment stand out and shows deeper understanding.
Conclusion
Assignments on Naive Bayes classifiers for resume selection give students a chance to combine theory with practical application. By following the steps outlined here—data preprocessing, pipeline creation, model training, evaluation, and interpretation—you can build a complete solution that demonstrates both your statistical knowledge and programming skills.
Such assignments not only improve your academic performance but also prepare you for real-world applications in data analysis, predictive modeling, and natural language processing.
If you find yourself struggling with complex steps like data preprocessing, tuning, or interpretation, remember that expert guidance is available. At statisticshomeworkhelper.com, we specialize in helping students solve challenging statistics and machine learning assignments with clear explanations and practical solutions.