How to Solve Assignments on Logistic Regression with NumPy and Python

Claim Your Discount Today
Get 10% off on all Statistics homework at statisticshomeworkhelp.com! Whether it’s Probability, Regression Analysis, or Hypothesis Testing, our experts are ready to help you excel. Don’t miss out—grab this offer today! Our dedicated team ensures accurate solutions and timely delivery, boosting your grades and confidence. Hurry, this limited-time discount won’t last forever!
We Accept









- Understanding Logistic Regression
- Preparing Your Workspace
- Exploratory Data Analysis (EDA)
- Example EDA steps:
- Implementing Gradient Descent from Scratch
- Performing Logistic Regression with NumPy and Python
- Data Visualization with Matplotlib and Seaborn
- Skills You’ll Practice
- Common Assignment Challenges and How to Overcome Them
- Bringing It All Together: A Student’s Workflow
- Final Thoughts
Assignments in statistics and data science often require students to move beyond theoretical understanding and apply practical programming skills to solve real-world problems. Among the most common tasks is logistic regression, a supervised learning algorithm widely used for predicting categorical outcomes such as whether a student passes an exam, whether a customer makes a purchase, or whether a patient receives a diagnosis. For students, the challenge lies not just in applying formulas but in mastering the full workflow, which includes implementing gradient descent from scratch, performing logistic regression with NumPy and Python, and creating meaningful data visualizations with Matplotlib and Seaborn. These steps allow students to gain hands-on experience in exploratory data analysis (EDA), Python programming, algorithm development, and machine learning, all of which are crucial skills for academic and professional success. At Statisticshomeworkhelper.com, we provide expert statistics homework help that guides students through these processes with clarity and accuracy, ensuring they understand both the theory and application. Whether you’re working on optimization, visualization, or performance evaluation, having the right guidance can make assignments less overwhelming. If you’re struggling, our team is ready to provide help with logistic regression homework tasks, making sure you achieve better results with confidence.

Understanding Logistic Regression
Before you dive into implementation, it’s important to understand the fundamentals of logistic regression. Unlike linear regression, which predicts continuous values, logistic regression predicts probabilities for binary outcomes.
For example:
- Will a student pass (1) or fail (0)?
- Will a customer buy (1) or not buy (0)?
- Will a patient test positive (1) or negative (0)?
The logistic regression model uses the sigmoid function:
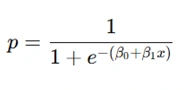
Here:
- pp is the probability of the positive outcome.
- β0 and β1 are parameters to be estimated.
Assignments often require you to implement the algorithm from scratch, giving you a deeper understanding of how machine learning models work internally.
Preparing Your Workspace
Most assignments will expect you to use tools like:
- Python (with Jupyter Notebooks for clean execution).
- NumPy for numerical computations.
- Pandas for handling datasets.
- Matplotlib and Seaborn for visualization.
A typical setup looks like this:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
This foundation allows you to load data, preprocess it, and get ready for modeling.
Exploratory Data Analysis (EDA)
Before running logistic regression, students are expected to perform EDA to understand the dataset. This step is critical because it shapes your modeling decisions.
Example EDA steps:
Load the dataset:
data = pd.read_csv("dataset.csv")
print(data.head())
Check for missing values:
print(data.isnull().sum())
Summarize statistics:
print(data.describe())
Visualize distributions:
Using Seaborn, you can plot histograms, boxplots, and correlation heatmaps.
sns.countplot(x='Outcome', data=data)
plt.title("Distribution of Outcome")
plt.show()
EDA not only helps you understand the dataset but also allows you to detect outliers, missing values, and variable distributions—all of which impact your logistic regression model.
Implementing Gradient Descent from Scratch
Many assignments explicitly ask you to implement gradient descent instead of relying on libraries like Scikit-learn. This is because it helps students learn the mathematical intuition behind optimization.
Steps:
Sigmoid Function:
def sigmoid(z):
return 1 / (1 + np.exp(-z))
Loss Function (Binary Cross-Entropy):
def compute_loss(y, y_pred):
m = len(y)
return -(1/m) * np.sum(y*np.log(y_pred) + (1-y)*np.log(1-y_pred))
Gradient Descent Algorithm:
def gradient_descent(X, y, lr=0.01, epochs=1000):
m, n = X.shape
theta = np.zeros(n)
losses = []
for _ in range(epochs):
z = np.dot(X, theta)
y_pred = sigmoid(z)
loss = compute_loss(y, y_pred)
losses.append(loss)
gradient = np.dot(X.T, (y_pred - y)) / m
theta -= lr * gradient
return theta, losses
Assignments may ask you to plot the loss function over iterations to confirm convergence.
plt.plot(losses)
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.title("Loss Curve")
plt.show()
This step ensures you’ve correctly implemented the algorithm.
Performing Logistic Regression with NumPy and Python
With gradient descent ready, you can now train and test your logistic regression model.
Splitting Data:
from sklearn.model_selection import train_test_split
X = data.drop("Outcome", axis=1).values
y = data["Outcome"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Training Model:
theta, losses = gradient_descent(X_train, y_train, lr=0.01, epochs=1000)
Making Predictions:
def predict(X, theta, threshold=0.5):
probs = sigmoid(np.dot(X, theta))
return (probs >= threshold).astype(int)
y_pred = predict(X_test, theta)
Evaluating Performance:
Assignments often require accuracy, precision, recall, and F1-score.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
print("Accuracy:", accuracy_score(y_test, y_pred))
print("Precision:", precision_score(y_test, y_pred))
print("Recall:", recall_score(y_test, y_pred))
print("F1 Score:", f1_score(y_test, y_pred))
This gives a complete workflow, from implementing logistic regression to testing it on real data.
Data Visualization with Matplotlib and Seaborn
Assignments don’t just stop at coding—they usually ask for visualizations to interpret your results.
Common Plots:
Scatter Plot of Predictions:
plt.scatter(range(len(y_test)), y_test, label="Actual")
plt.scatter(range(len(y_pred)), y_pred, label="Predicted")
plt.legend()
plt.title("Actual vs Predicted Outcomes")
plt.show()
Confusion Matrix Heatmap:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues")
plt.title("Confusion Matrix")
plt.show()
Loss Function Curve (as shown earlier):
Visualization not only makes your assignment more professional but also helps explain your findings clearly.
Skills You’ll Practice
When solving logistic regression assignments, you’re not just coding—you’re building a suite of essential data science skills:
- Exploratory Data Analysis (EDA): Understanding dataset structure, distributions, and relationships.
- Data Visualization: Using Matplotlib and Seaborn for graphical insights.
- NumPy Proficiency: Handling arrays and numerical operations efficiently.
- Algorithm Implementation: Coding gradient descent deepens algorithmic intuition.
- Machine Learning Concepts: Logistic regression is foundational in supervised learning.
- Python Programming: Practicing clean, modular coding in Jupyter.
- Data Analysis: Moving from raw data to meaningful conclusions.
These skills not only help you ace assignments but also prepare you for real-world applications in finance, healthcare, marketing, and beyond.
Common Assignment Challenges and How to Overcome Them
Students often face roadblocks while working on logistic regression assignments. Let’s look at common issues:
- Poor Model Accuracy:
- Gradient Descent Not Converging:
- Overfitting:
- Complex Code:
Solution: Check for missing values, outliers, and feature scaling.
Solution: Reduce learning rate, increase epochs, or normalize features.
Solution: Use train-test split, regularization techniques, or more data.
Solution: Break down code into functions for readability and debugging.
At Statisticshomeworkhelper.com, we often see these challenges in student assignments and guide them toward clean, optimized solutions.
Bringing It All Together: A Student’s Workflow
Here’s a simple roadmap you can follow for any logistic regression assignment:
- Understand the problem statement (binary classification task).
- Load and clean the dataset (handle missing values, outliers).
- Perform EDA with Pandas, Matplotlib, and Seaborn.
- Implement logistic regression with gradient descent using NumPy.
- Train and test the model with a dataset split.
- Evaluate performance metrics like accuracy and recall.
- Visualize results (loss curve, confusion matrix, scatter plots).
- Summarize findings (insights and limitations).
This systematic approach ensures you cover all assignment requirements.
Final Thoughts
Assignments on logistic regression are designed to strengthen your foundation in machine learning algorithms, Python programming, and statistical analysis. By implementing gradient descent, using NumPy for computations, and applying visualization techniques, you’ll not only complete your assignments but also build practical expertise.
At Statisticshomeworkhelper.com, we support students in solving such assignments with clarity, precision, and guidance. Logistic regression isn’t just an academic requirement—it’s a stepping stone to advanced machine learning concepts like decision trees, random forests, and neural networks.
If you’re struggling with your logistic regression assignment, remember that the key lies in breaking the problem into steps: EDA → Implementation → Evaluation → Visualization. With practice, you’ll find these assignments less intimidating and more rewarding.